cyclical learning rate 学习
前段时间,忘了自己从哪里看到的这个论文:joy::joy::joy:。反正就先记录一下吧,这篇论文也不难。
讲的就是调节学习率的一种方法,加快收敛,无需调整通常可以减少迭代次数。不再需要我们寻找最合适的学习率。Cyclical learning rate翻译过来就是循环学习率(CLR),顾名思义,意思就是让学习率在一个范围内来回变化,不同于其他的学习率固定或者单调递减变化学习率,它是以一种周期的方式变化。这种方法消除了调整学习率的需要,但是也实现了接近最佳的分类精度。
主要贡献
- 一种设置全局学习率的方法,不用大量实验就可以找到最佳的值和策略,不需要额外的计算。
- 证明了学习率的反复升降是有益的,即使他可能暂时损害网络性能。
- 在CIFAR10和CIFAR100对ResNets, Stochastic Depth networks, DenseNets, 在ImageNet对AlexNet、GoogLeNet进行了验证
CLR
相关工作部分是介绍了一些自适应学习率,我直接跳过了。直接看的第三部分。
这个策略的本质来自于一个观察,提高学习率可能会在短期内产生负面影响,但在长期内是产生有益的影响的。受到启发,让学习率在一定的范围内变化,而不是使用逐步固定或指数递减的值。文章中做了大量实验,采用triangular window(三角窗,线性), a Walch window(韦尔奇窗, 抛物线),a Hann window(汉恩窗,正弦),结果都差不多。最终使用的是triangular window,较为简单。
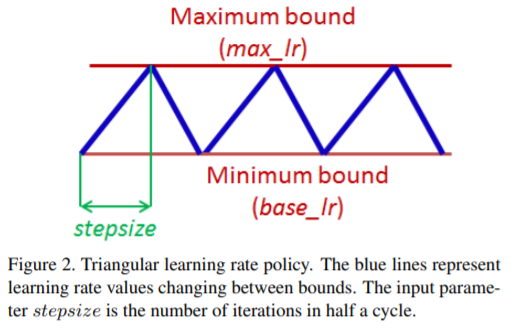
CLR有用的原因
Dauphin等人认为损失最小化的难点是来自于鞍点而不是局部最小值,鞍点有很小的梯度,减慢了学习过程。而增加学习率可以快速跳过鞍点。一个更加实际的来解释为什么CLR有用的原因是,通过论文3.3部分(如何能够一次估计合理的最小最大边界值)的方法,可能最优的学习率在这个边界内,接近最优的学习率在整个训练过程中被使用。
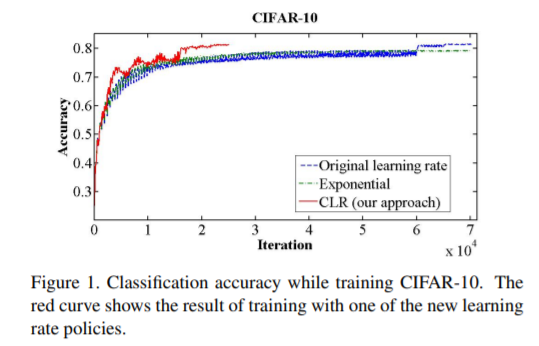
图一当中红色为CLR,可以看出CLR使用更少的迭代达到了相同的准确率。文中的实现伪代码这里我就不写了,CLR在pytorch中已经有实现好的了。
如何估计一个好的循环长度
一个循环长度和输入参数stepsize可以从一个epoch的迭代次数中简单计算出来。样本数/batchsize。比如CIFAR-10有50000个样本, batchsize是100,所以一个epoch是 50000 / 100 = 500次的迭代。实验表明通常设置stepsize为2 ~ 10倍的一个epoch的迭代数量比较合适。一般训练3论就差不多,4轮以上会更好。停止训练的时候最好在cycle的结尾,并且准确率达到峰值。
小总结:
stepsize = (2 ~ 10)*(样本数/batchsize)
训练轮数:3+
停止时间:cycle结尾,acc达到peak
如何估计一个合理的最大最小边界值
有一个简单的方法用一次很少的epoch训练,去估计合理的最大最小边界值。LR range test: 用你的模型跑几个epoch,同时让学习率从小到大线性增加。当面对一个新的结构或数据集的时候,这个测试十分有价值。
学习率在短期内从最小值线性增加到最大值,然后绘制准确率和学习率的关系图。当准确率开始增加,开始放缓,变得抖动,或者开始下降时,注意学习率的值。这两个学习速率是上界最好的选择。另一个经验之谈,最佳学习率通常收敛于最大学习速率的两倍之内。设置base_lr = 1/3 or 1/4 max_lr
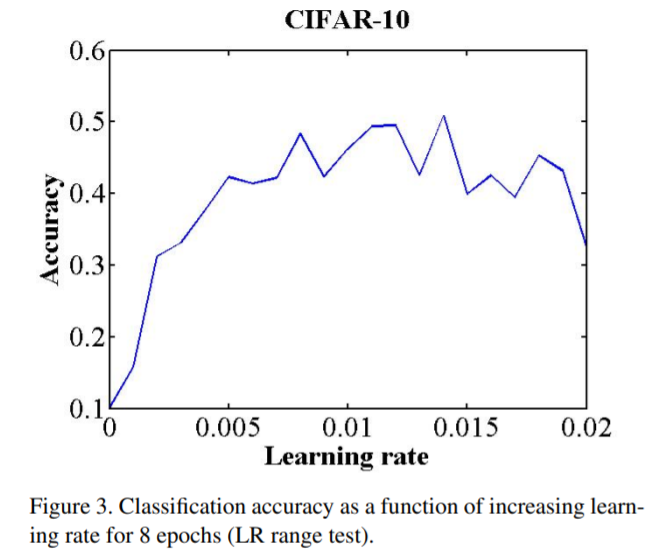
如图为论文中的例子,使用的CIFAR-10的数据集,使用的结构和超参都是Caffe提供的。可以看出模型立即开始收敛,因此设定base_lr = 0.001是合理的,在0.006的学习率上,准确率的上升变得困难,最终开始下降,因此设定max_lr = 0.006比较合理。
代码应用
看了这么些,当然有些手痒痒,想试一下看看是否正如作者所说的那样。为了想快点看效果,我就找的比较小的一个花数据集简单跑一下。
LR range test
先按照论文说的跑个测试看看,pytorch提供的CLR是
1 | torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr,max_lr,step_size_up=2000,step_size_down=None,mode='triangular',...) |
我是用的是ResNet18,flower数据集,SGD的优化器,学习率默认为0.02。但是做这个测试的时候使用的是0.001和0.08。跑8个epoch,因此设定step_size为 (len(train_data) // batch_size) * 8。因为是线性增加,因此只用填step_size_up参数,down部分不填。得到acc-lr图
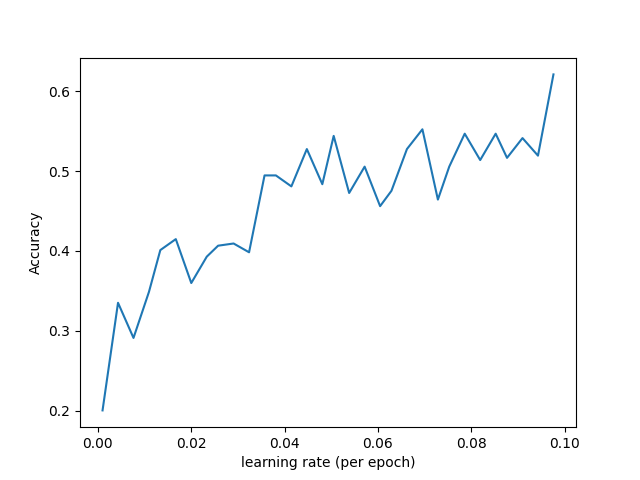
在这里我看来,当学习率在0.05左右基本趋于稳定,因此后面正式训练的时候把max_lr设定为0.05,min_lr设定为0.001
代码:
1 | # 上边加载图片,预处理,设定设备,等操作没写在这里。 |
训练代码
1 | gd_optim = optim.SGD(net.parameters(), lr=base_lr) |
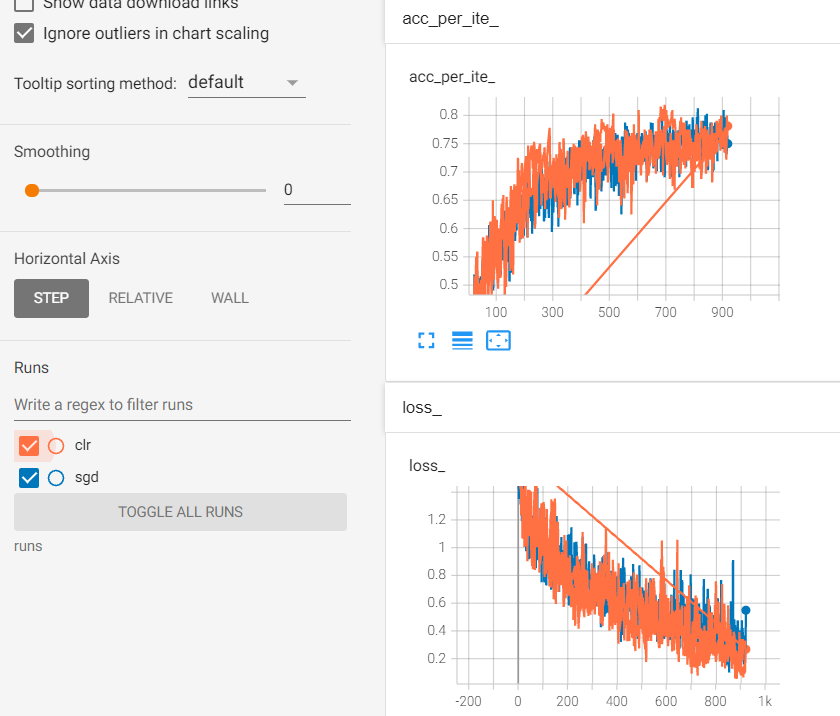
额,这个是对比图,蓝色是原始sgd,橙色是clr,橙色多的两条直线无视他吧:joy:,是我用tensorboard之前尝试其他的写错了点东西导致的。感觉优势并不是很明显,不知道是不是epoch少了导致的。但是能大概看出损失部分橙色略低于蓝色,准确率上是差不多。
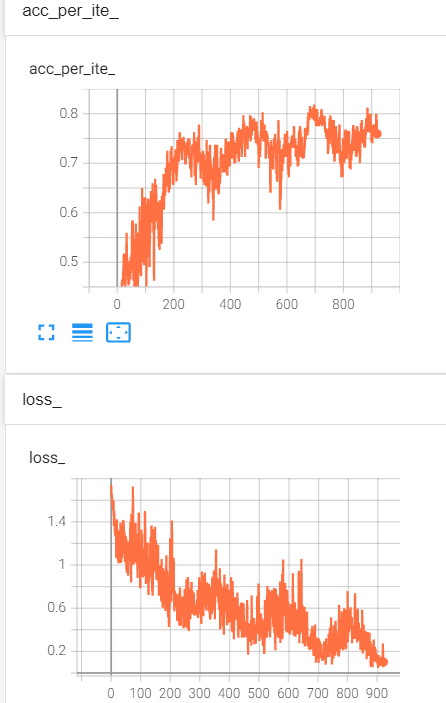
这个是之前的曲线,准确率也是周期性的变化上升,损失也是周期性下降:smile: