LinkNet学习及实现
LinkNet的论文篇幅不多,网络也很简单。首先说一下应用背景,LinkNet想要做的任务是实时的图像分割。就是需要响应时间短,准确率高的一个网络。虽然现在的算法都可以达到很高的准确率,但是都没有把重点放在有效的利用神经网络的参数上。在参数和操作数量方面很多,导致了缓慢。实时的场景理解和图像分割可以应用在自动驾驶,增强现实等场景。
引言和相关工作
由于增强现实和自动驾驶汽车等任务的激增,许多研究人员已经将他们的研究重点转向场景理解,其中涉及的一个主要步骤是像素级分类/语义分割。受到Auto-Encoder的启发,大多数的现有的语义分割技术使用的是encoder-decoder的结构。Encoder将信息编码到特征空间,解码器将这些信息映射到类别空间用来分割表示。尽管语义分割针对的是需要实时操作的应用程序,讽刺的是大多深度网络需要大量的处理时间。像YOLO,Fast RNN,SSD专注于实时对象检测,但在语义分割上几乎没有任何工作。
论文中分析,由于池化和卷积导致的控件信息丢失,可以由反池化或全卷积(就是反卷积)恢复。绕过空间信息,直接将encoder结果给到相应的decoder中去,提高了精度,减少了处理时间。其实说的就是特征融合的方式。然后生成器一般要么是用判别器中存的池化索引要么就是反卷积进行上采样。
在SegNet中使用了预训练的VGG作为判别器。每次的最大池化后都会保存池化索引,然后在解码器中上采样的时候使用。再后来的研究人员提出了深度反卷积网络,FCN结合跳跃结构的思想,认为反池化其实没有什么需要的了。标准的预训练编码器都已经被用于分割了,为了得到更精确的分割边界,添加了后处理步骤级联,比如使用条件随机场CRF(Conditional Random Field)
网络结构
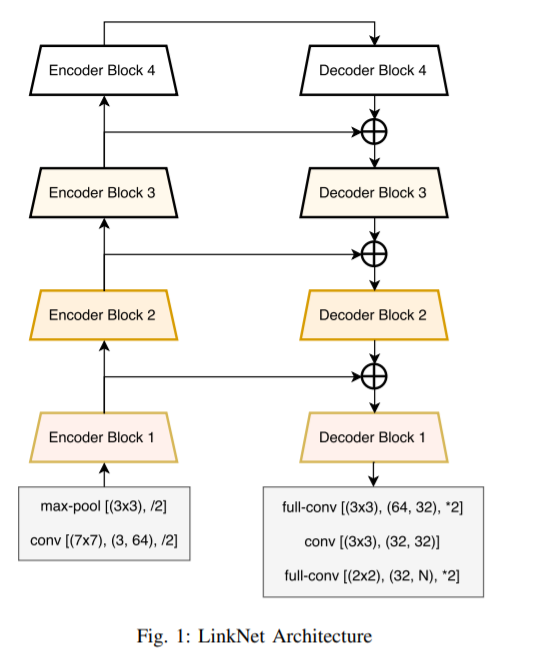
LinkNet的结构看图就已经很清楚了,将每一层编码器的结果保存一份,再在解码器解出的结果和对应的编码结果加和,传入下一层解码器中去。
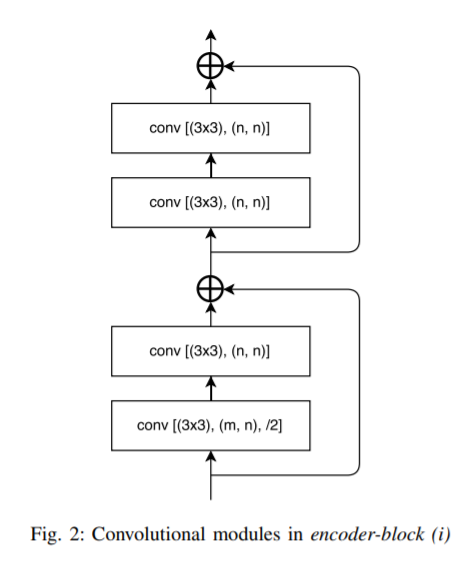
这个是Encoder的结构,一看就觉得很熟悉,这不就是残差块嘛,编码器的4个Encoder-block之后,不就是ResNet18么。没错,论文里直接说了LinkNet使用的是ResNet18作为Encoder。:joy::joy::joy:
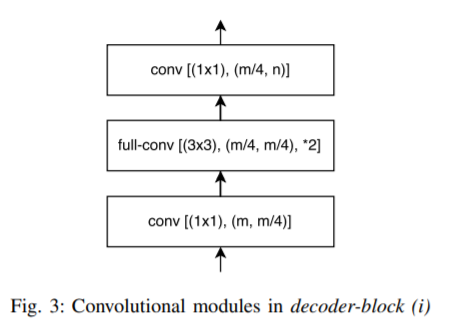
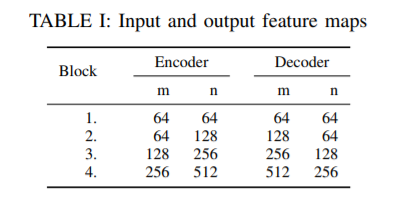
代码实现
1 | import torch |
参数设置
学习率:5e-4
优化器:RMSProp
参考资料
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation