GoogleNet学习及实现
GoogLeNet也是比较经典的一个分类网络。这篇论文也是少有的有彩蛋的论文:happy:。起名为GoogLeNet也是致敬了LeNet经典的CNN网络。GoogLeNet又名(InceptionV1),主要基于赫布理论和多尺度信息处理。这个网络主要在于增加了网络深度和网络宽度,同时减少了参数量和计算量。GoogLeNet相比AlexNet参数量减少了12倍,精度有所提高。起名InceptionV1,这个Inception一词是来源于《盗梦空间》电影。同时这个论文第一个引用居然是一个网络热词。。。

“We need to go deeper”有两个意思:1. 使用了新的inception模块,2. 加深了网络深度。用稀疏分散的网络取代以前庞大密集臃肿的网络。
灵感来源
LeNet5,卷积神经网络CNN这种经典的标准结构,通过堆叠卷积层,归一化层,池化层。使用DropOut解决过拟合问题。不断加深网络从而达到更好的效果。虽然池化层丢失了空间像素精确信息,但仍然能够很好的完成定位和目标检测。受到神经科学研究成果启发,相似与视觉皮层上的神经元,每个神经元只关注不同的特征。多个卷积层以不同尺度关注不同特征,最终经过汇总融合。也就是Inception模块的思想。比如,识别一只猫,有的神经元关注猫眼睛,有的关注猫尾巴,有的关注猫的耳朵,如果真的是一只猫,那么这些神经元应当同时被激活。就如同赫布学习法则,神经突触间的用进废退。
从Network in network中得到启发,使用1 x 1卷积核进行降维操作,1 x 1卷积的作用: 降维、减少参数量、增加模型深度提高非线性表达能力。
Inception结构
原始结构
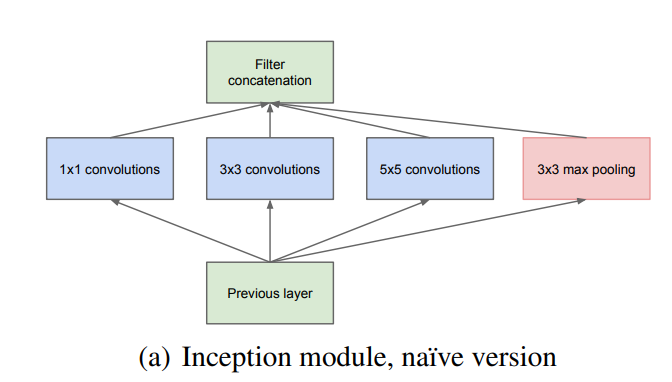
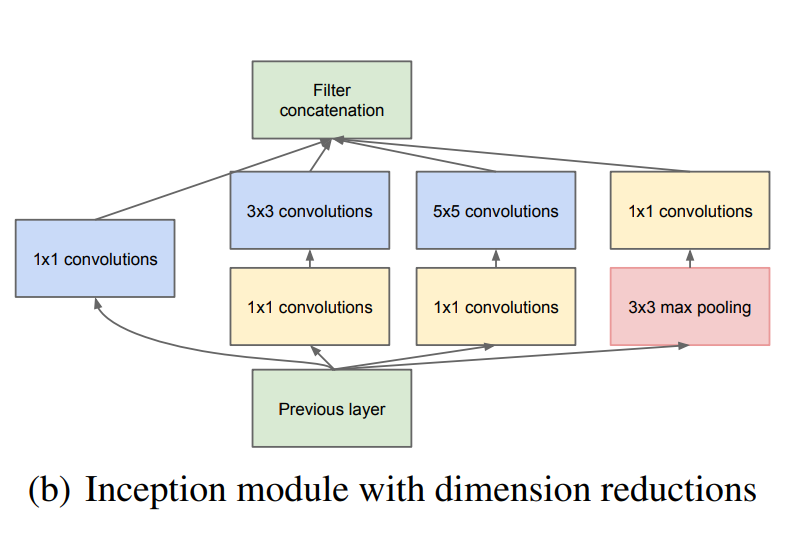
结构中分别采用了1、3、5的卷积核,为了方便对齐,设定stride为1之后,只要padding为0,1,2即可。不同的卷积核有着不同的感受野不同的尺度特征进行融合,也就是拼接在一起。但是不断堆叠的通道数量,导致计算量的不断增大。因此使用了Network in Network中的1 x 1卷积核进行降维操作,而且该卷积核可以放在任意位置。但是为了降低计算量,GoogleNet将1 x 1卷积分别放在了3 x 3和5 x 5的前边。改进之后
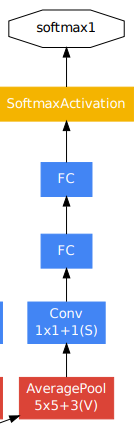
辅助分类器
由于网络较深,有效的反向传播所有层的梯度是一个问题。通过浅层的辅助分类器,让早期的浅层特征表现出足够的区分性。同时提供了额外的正则化。这些分类器被放在Inception(4a)和(4d)的输出上。这两个辅助分类器的损失都是乘上一个0.3的权重加在总损失上。也就是loss总 = loss_last + loss_aux1 0.3 + loss_aux2 0.3。在测试阶段去除了辅助分类器,只用主干完成输出。(后续被证实辅助分类器没太大用处,也被去掉了)
结构:
- 5 x 5的核,步长为3的平均池化层,对于(4a)输出一个 4 x 4 x 512,对于(4d)输出一个4 x 4 x 528
- 一个1 x 1卷积的128个滤波器进行降维和线性激活 (简单说就是1 x 1 x 128卷积,Relu激活)
- 一个有1024个单元的全连接层和线性激活 (in: 2048 out: 1024 的全连接,Relu激活)
- 70%dropout层
- 一个使用softmax的线性层作为分类器(in: 1024 out: num_classes,Softmax)
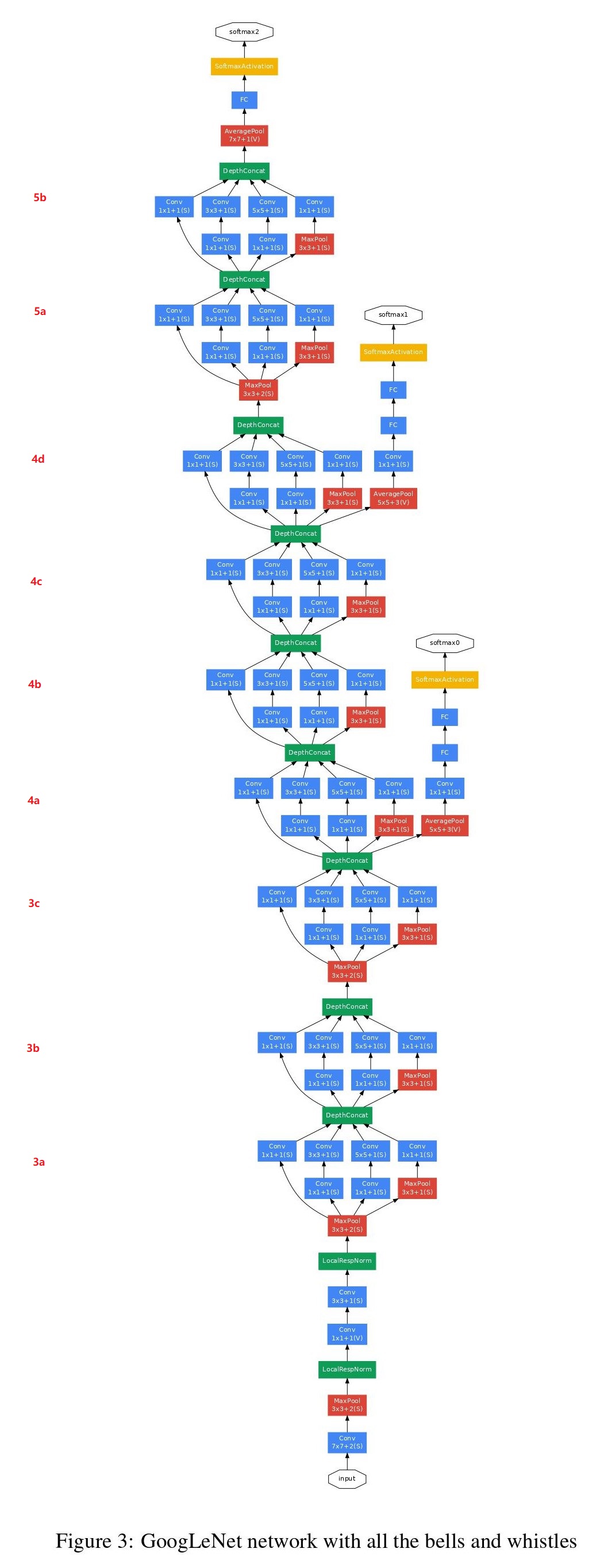
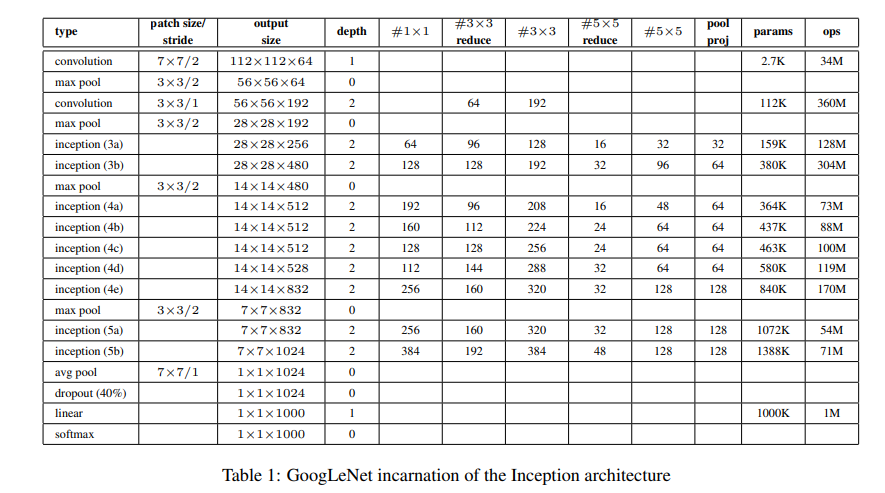
GoogLeNet结构
详细参数:
代码实现
网络结构实现,参考的5.2 使用pytorch搭建GoogLeNet网络,我使用的是之前的猫狗识别数据集。为了提高训练速度,使用了2张显卡做的训练。两张3080显存总共20G,batch_size设定的128,学习率0.001,Adam优化器,betas=(0.4, 0.999)。多卡训练使用的是nn.DataParallel详情见pytorch常用方法记录。