CGAN学习及实现
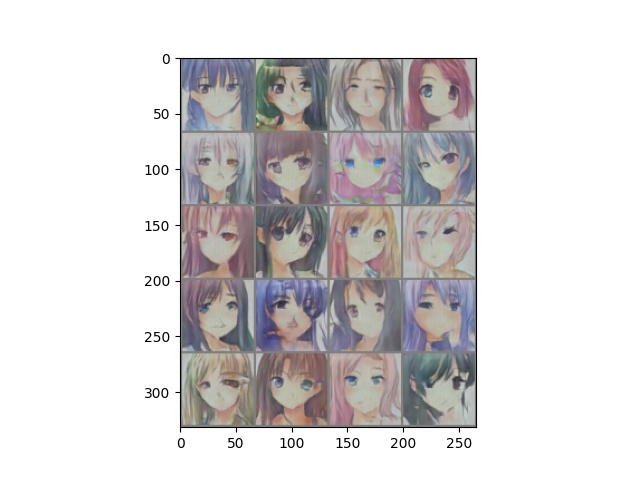
在GAN的学习中,生成了随机的二次元人物头像。人物随机生成,随机生成的人物不可控,如何让Generator按照我们想的样子的二次元头像呢。这里使用了CGAN(conditional GAN)条件GAN完成这个任务。
效果图
这个是跑了150个epoch的效果,训练集和写GAN的那篇用的是一样的。
CGAN思想
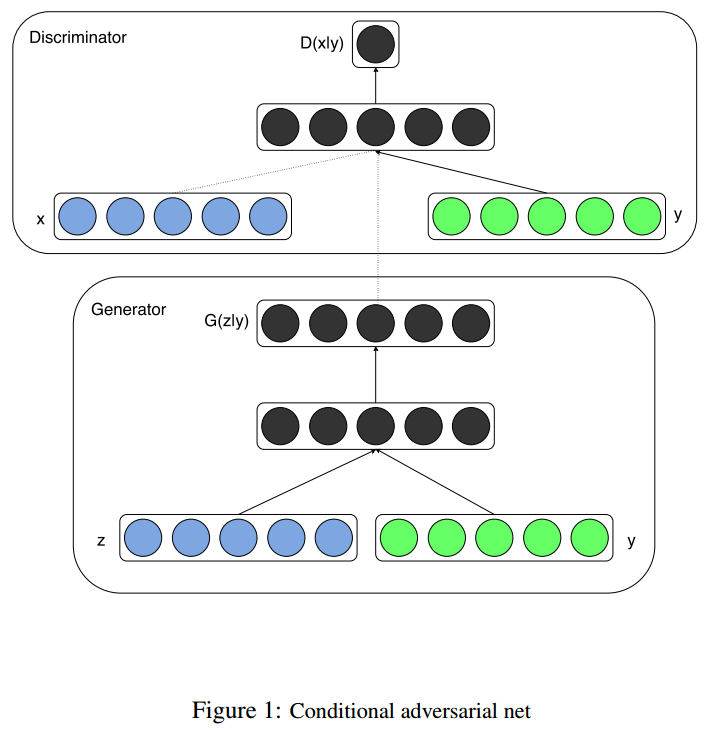
这个图网上到处都有,一搜全都是。我也简单说一下吧。CGAN是在原始GAN的基础上,在训练生成器G和判别器D的时候都加入了新的条件变量y,y可以是各种信息,标签等信息。y在训练过程中起到指导作用。
图中的做法是,对于生成器G,将y条件信息,和noise拼接,放入生成器中用来生成图片。对于判别器D,将y条件信息和x图像信息拼接。拼接方式可以是用全连接将类别转为相应大小的图片,拼接到原图片的通道当中,然后继续和GAN的D一样进行评分。这个是网上很多人的做法,我的代码也使用的这个。不过我觉得也可以是,图片经过一个网络生成embedding,label通过一个网络生成一个Embedding然后两个特征相组合在进行评分也可以。
训练的细节
训练目标
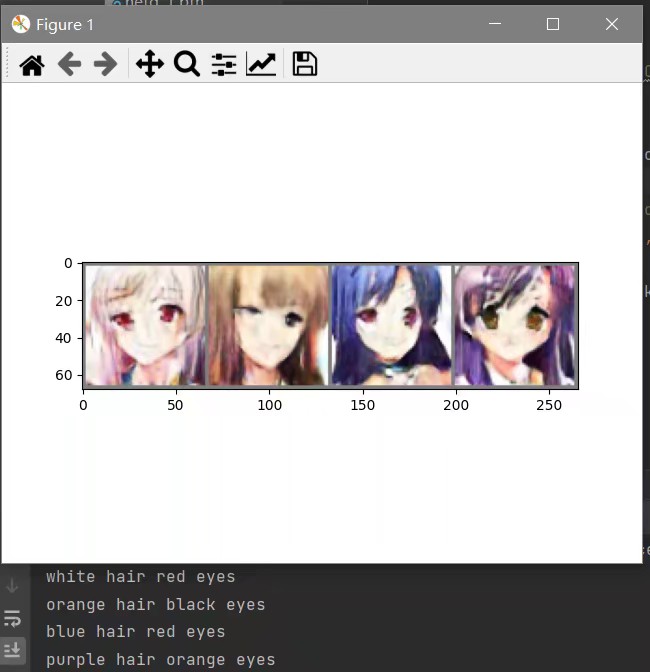
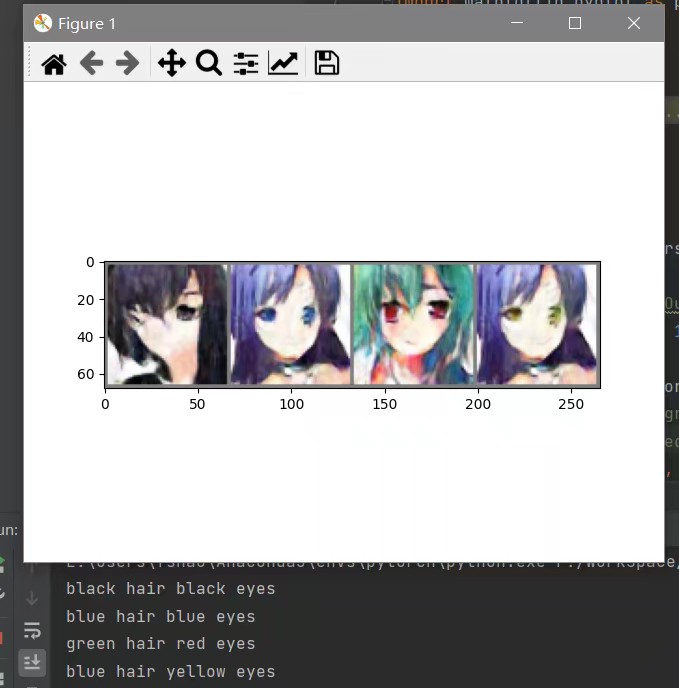
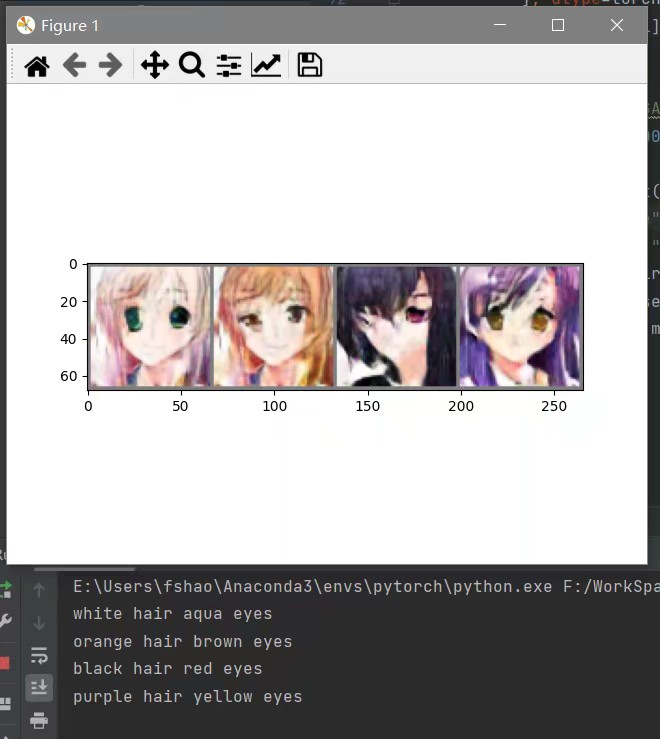
根据输入的头发颜色,眼睛颜色,让Generator生成出对应的二次元头像。
使用的数据集
这里用的是和GAN那篇一样的,需要用到tags.csv
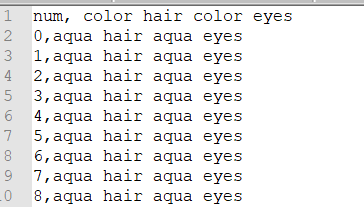
最上面的一行是我自己加的。tags格式为:图片号,头发颜色 hair 眼睛颜色 eyes。读取csv使用的是pandas的包,没有的可以自行安装
1 | pip install pandas |
读csv格式标签的方法。
1 | import pandas as pd |
开始训练
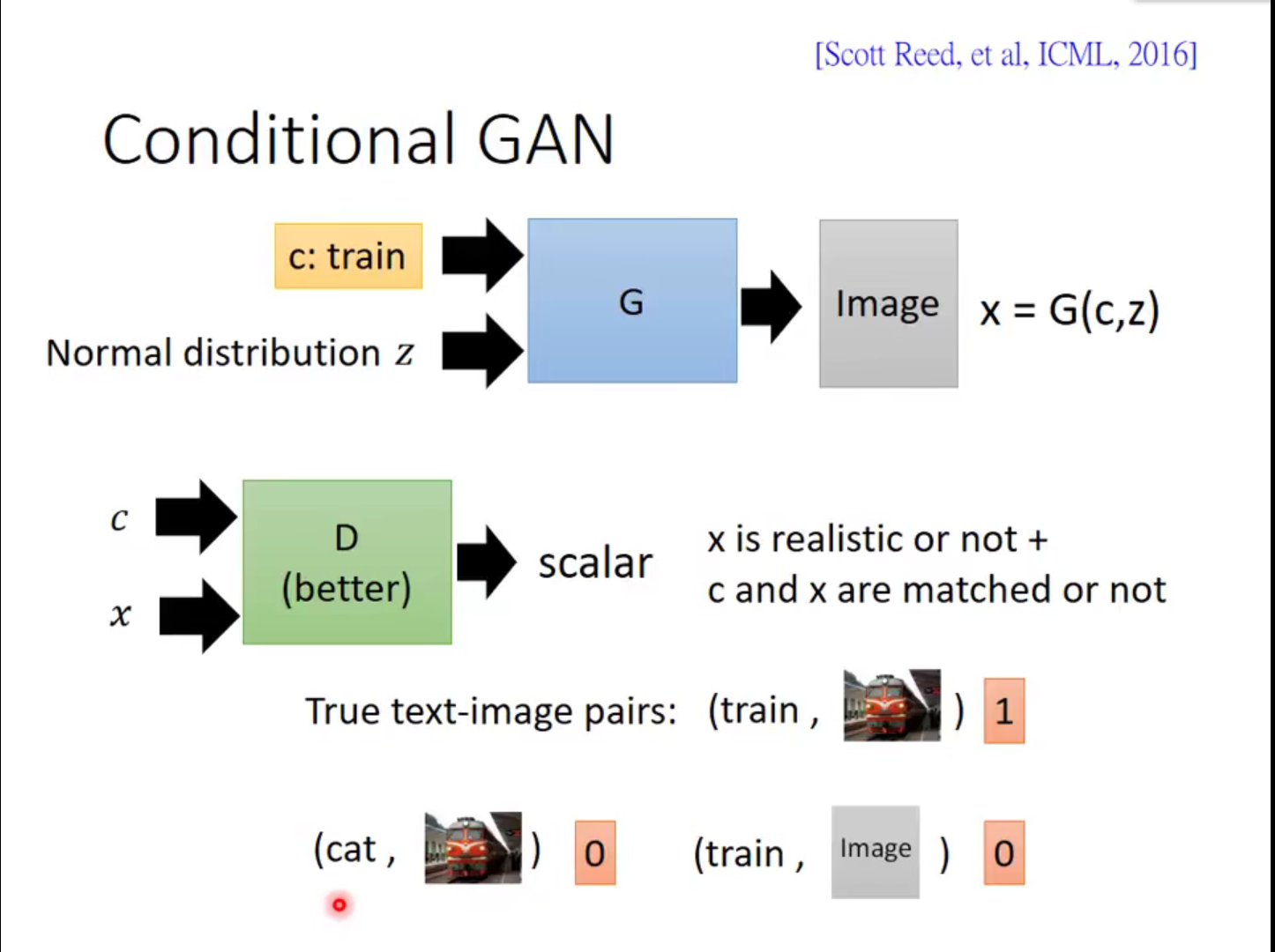
这里是训练判别器D的方式,不同于GAN那样,只判断图像是否为二次元头像。这里需要想到几个问题:这个图片是否清晰,这个label条件是否正确。需要考虑三种情况,也就是三个loss:
第一种,我们先给D一个训练集当中的图片,和对应的label。此时是最好的情况(图片清晰,条件正确),我们应当给高分,让它靠近1.
第二种,我们给G一个随机noise加上当前的label,让它产生out图片,此时的图片变得不清晰,但是label是正确的。将out图片和label送给D评分,此时分数应当降低,让它靠近0
第三种,我们重新从数据集当中选出和当前label不一样的图片,这时属于是label错误(图片足够清晰,条件错误),D同样需要给他低分。
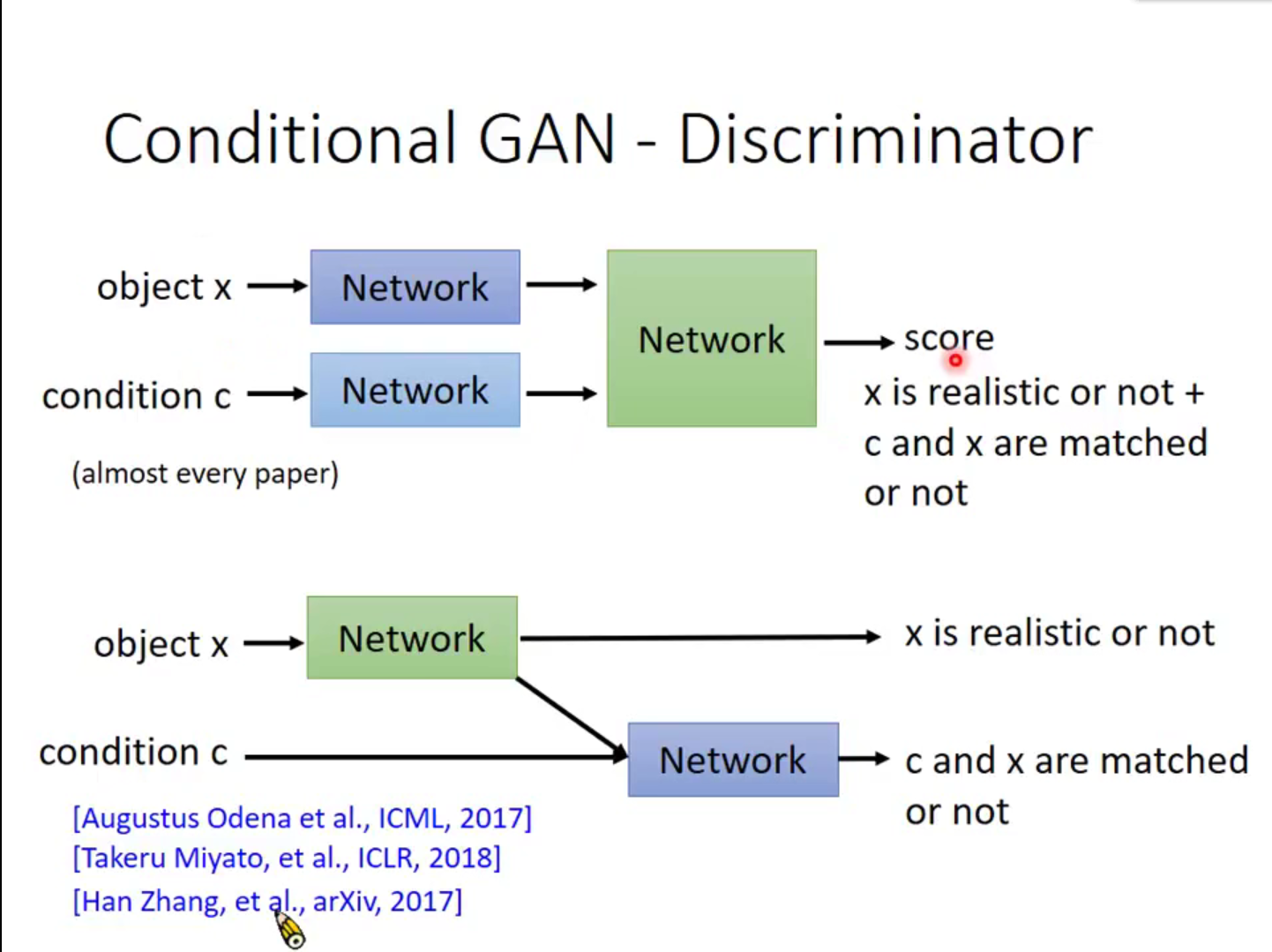
这个是两种评分方式,第一种上面的是常用方法,图片和条件分别产生Embedding然后合拼到新的网络中产生分数。第二种是李宏毅老师说的方法,觉得更符合逻辑一些。这个做法是,一个图片经过一个网络,产生一个图像分数(用来判定图像是否清晰)和一个Embedding特征,将特征和条件结合,进入新的网络,产生图像和条件是否满足的分数。这样让网络知道是哪个部分导致的分数降低,从而达到更好的效果。这个我打算去实现以下,做个尝试。

这个是整个训练过程:(c代表条件label,x代表图片,z代表随机噪声)
D训练
- 从数据集选择m个正向样本。
- 产生m个随机noise样本
- 获取生成数据,将noise和条件c加入G中产生新的图片
- 从数据集中获取m个新的图片。
- 更新判别器参数,下面的公式可以那GAN那篇的方式来看。
G训练
- 产生m个随机噪声样本noise
- 从数据集中拿到m个条件c
- 用noise和c产生图片,放入D中评分,让评分靠近1
代码实现
一些参数配置,这里用的label是one-hot形式,2 x 13的大小,总共13种颜色,第一行是头发颜色,第二行是眼睛颜色。
1 | def generateLabel(hair_colors, eye_colors, one_hot=False): |
ConditionalGANSet.py
1 | import pandas as pd |
Generator
1 | class Generator(nn.Module): |
Discriminator
1 | # 定义鉴别器网络D |
训练
1 | generator = Generator().to(device) |