ResNet学习及实现
最近想学下Cycle GAN,然而Cycle GAN当中应用到了ResNet相关的知识,查了下ResNet还是蛮重要的,干脆先学了ResNet。本篇记录学习Res残差网络相关的知识,通过网上的视频以及知乎大佬的解释学习的。链接放在后面。
什么是残差
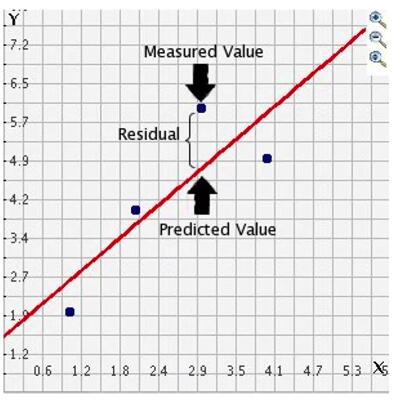
ResNet(Residual Network)残差网络,残差指的就是实际值和预测值之间的差距。这个网络的意思就是训练的网络不再拟合原始数据H(x),而是拟合的是上一层网络和预测值之间的残差。
残差网络解决的什么问题
网络退化
深度神经网络难以训练,同时深度越深的网络,可以通过堆叠网络层数提取的特征更加丰富。然而网络越深带来了新的问题。更深层次的网络模型效果却不如层次较少的网络。
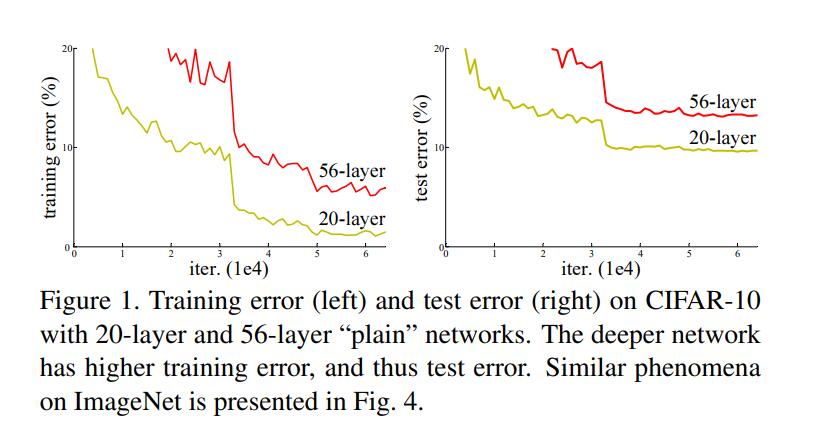
这个是论文中的图表,左侧是训练,右侧是测试。在CIFAR-10中,56层和20层的简单神经网络比对。很显然,56层的错误率比20层要高,层数越深反而效果更差。这里既不是梯度爆炸/消失,也不是过拟合。而是网络退化。
什么导致的网络退化
当堆叠模型时,模型层数越多觉得就会越好,因为当一个浅层网络已经能够达到一个很好的效果时,我们也会认为即便后面更多的层数什么都不做,至少能保证不比现在差。然而问题就出现在什么都不做,神经网络很难做到什么都不做。“什么都不做”的意思简单说就是啥也不干,原样输出,就是恒等映射。ResNet的初衷就是让神经网络拥有恒等映射的能力。
残差网络
前面说的ResNet解决的是神经网络没有恒等映射的能力,因此ResNet是由如下的残差块完成的,相当于说上一个模型传进来,通过一个浅层模型加上一个恒等映射求和在输出,这样可以保证至少不比现在差。因为如果上一个模型传下来的效果已经很好了,我完全可以将这层浅模型的参数调为0,完全变成了恒等映射进行输出。
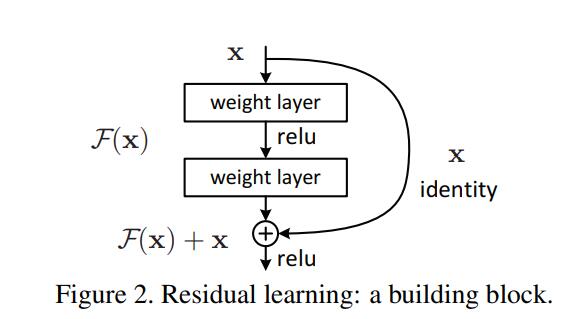
如上图,为一个残差块,右边是short Cut Connection(短连接),也就是恒等映射,就是将上层输出直接和下层输出加和汇总输出。因为这里不再拟合原始函数H(x),而是拟合的F(x)残差函数,F(x) = H(x) - x,转换后的到H(x) = F(x) + x ,所以在拟合的时候使用的 F(x) + x去拟合H(x)即可,这里要注意一下,中间的浅模型至少是两个,不然会发生很有意思的事,假设中间第一层是W1x,第二层是W2x,正常情况是W2(W1x) + x。如果只有一层的话就变成,W1x + x = (W1 + 1)x,这里W1和W1 + 1没区别了。
网络结构及维度

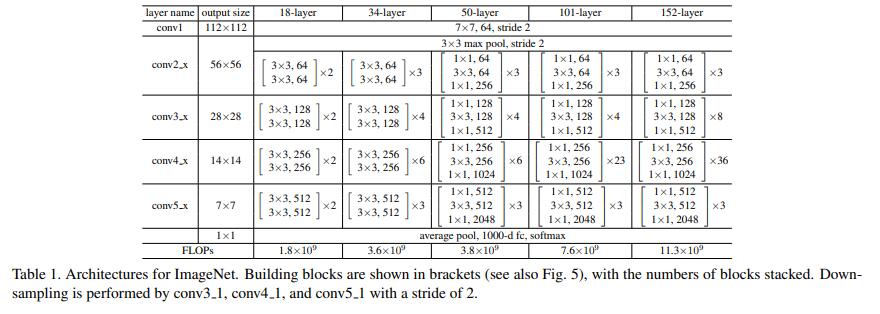
这个是论文中的34层网络,其中实线部分的shortcut是直接将输入的数据恒等映射加到下层输出中,汇总输出。虚线部分的shortcut都是出现在下采样,提升维度。所有的/2的意思就是图像大小缩小一倍,维度提升一倍。这个是采用和VGG一样的做法。因为中间卷积之后尺寸改变维度提升,无法和输入相加,所以输入需要提升维度。这里有三种方案:
A: x维度增加,用0填充空缺维度。
B: x维度增加,用1 * 1的卷积核提升维度。
C: 所有的Short Cut都使用1 * 1卷积
效果是C > B > A,其实影响并不大,我后面代码中使用的是B方案。
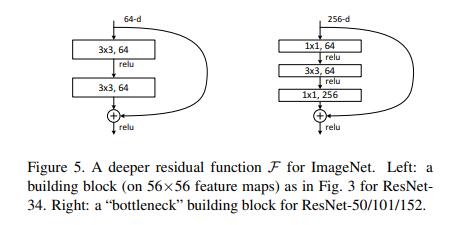
这里是残差块的选择,第一种是基础的残差块,通常用于ResNet-18和ResNet-34,第二种通常用于ResNet-50/101/152
各种ResNet网络结构
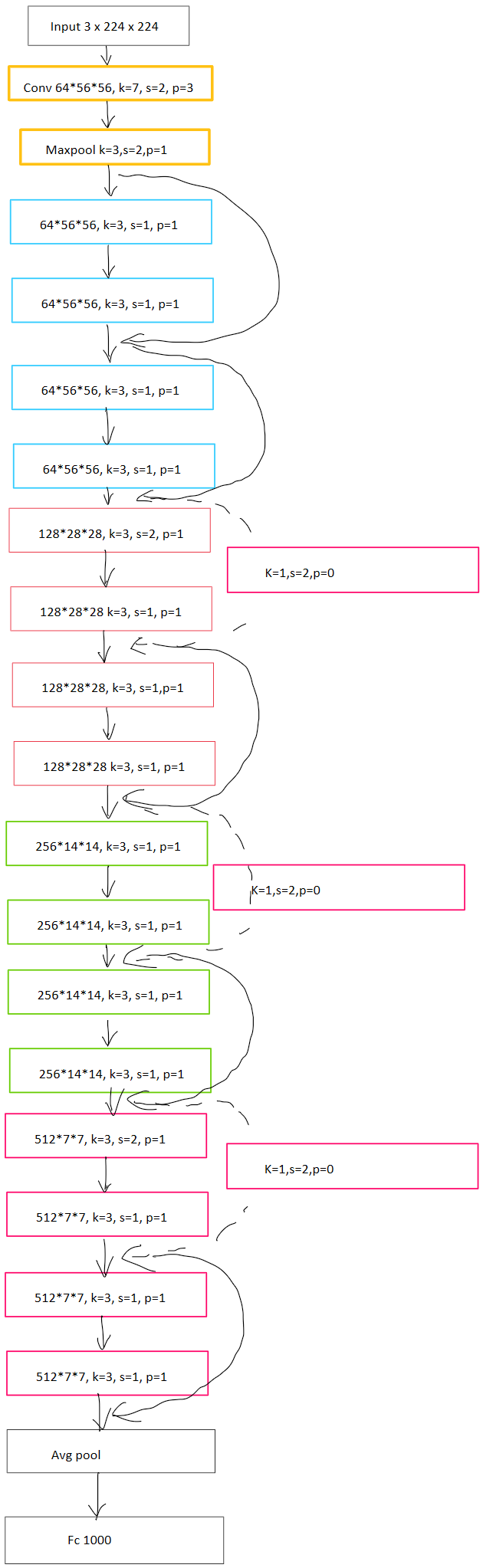
ResNet-18
这里我画一个详细的ResNet-18网络结构,方便后面代码实现。其中每个ResBlock中第一层conv后需要做一次BN,然后ReLU激活,进入第二层,第二层之后直接和输入相加,之后再激活。
代码实现
ResNet代码部分
首先是先写一个残差块
1 | class BaseBlock(nn.Module): |
这个就按照图画的来就行。每个残差块对输入输出通道进行判断,如果通道数变了,提升维度了,就修改对应的输入值的维度,进行汇总。
接下来是ResNet
1 | class ResNet18(nn.Module): |
最后的sigmoid可有可无,因为总是取最大概率的类别作为最终结果。而概率就是由这个全连接层输出值大小决定的。
实战训练猫狗识别
这里用的猫狗识别数据集是kaggle注册及下载里面讲的数据集。使用了2万张猫狗图片,测试集是2千张。
代码:
1 | import torchvision.utils |
经过25个epoch,在测试集上表现正确率达到90%以上。
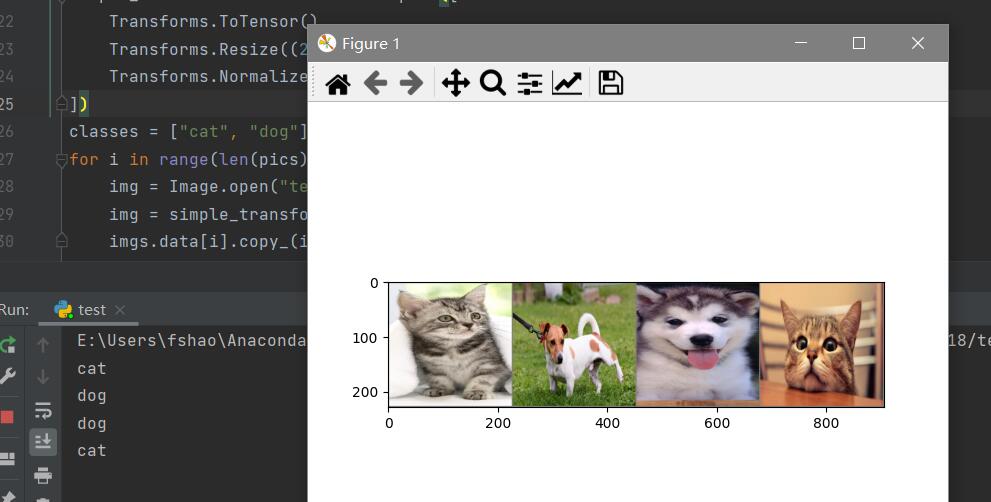
测试训练结果
网上随机下载几张图片测试。
测试代码:
1 | import torchvision.utils |
结果: