- 1. pytorch常用方法记录
- 1.1. 常用损失函数
- 1.2. 常用激活函数
- 1.3. 各种层
- 1.4. 常用方法
- 1.5. 调试工具
pytorch常用方法记录
本篇记录在学习使用pytorch时,常用的东西记录,以便随时查看。遇到新学到的会更新在这里。
常用损失函数
交叉熵CrossEntropyLoss
计算公式:
这个公式在深度学习入门04中讲过。
python代码:
1 | cross_entropy_loss = torch.CrossEntropyLoss() |
注意:CrossEntropyLoss的输入就直接是Model的输出,不要是softmax之后的。还有就是label必须是long类型在[0, class-1]之间。

查看源码中的解释即可知道,CrossEntropyLoss = log_softmax + NllLoss,因此不需要softmax。其中的C代表的类型。
均方差MSELoss (L2Loss)
计算公式:
1 | mseLoss = torch.MSELoss() |
BCELoss
bce loss分类,用于二分类问题。数学公式如下
pytorch中bceloss
1 | class torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean') |
weight: 初始化权重矩阵
size_average: 默认是True,对loss求平均数
reduction: 默认求和, 对于batch_size的loss平均数
L1Loss (MAE)
指的是一范数损失,也叫MAE,就是估计值和目标值做差的绝对值
公式:
1 | l1_loss = nn.L1Loss() |
常用激活函数
Sigmoid函数
公式:
代码:
1 | nn.Sigmoid() |
ReLu函数
ReLU函数:在输入大于0时,直接输出该值;在小于等于0时为0
公式:
代码:
1 | nn.ReLU(inplace= False) |
inplace若为True,则覆盖之前的值,可以减少内存消耗。
LeakyReLU
虽然relu在SGD中收敛很快,但是对于小于0的值梯度永远是0,那么激活函数收到的值通常都会有bias,如果偏置很小,导致值一直都是负数,使得梯度无法更新,最终导致神经元“死亡”。所以提出了LeakyReLU,当x小于0时不再等于0而是等于一个weight x。通常这个权重取0.2
$
y = max(0,x) + weight min(0,x)
$
代码:
1 | nn.LeakyReLU(0.2) |
各种层
二元自适应均值汇聚层
在实现ResNet的时候,看了下pytorch里面的ResNet源码,看到平均池化层使用的是nn.AdaptiveAvgPool2d((1, 1)),就觉的好奇查了下。
其实就是平均池化层,好处就是不需要我们自己算平均池化的步长啊,核大小啊,填充啊这些,只用传入一个我想要的大小,其他都是去自适应,还是蛮舒服的哈:happy:
常用方法
torch.squeeze()
对数据的维度进行压缩,去掉某行或某列。只能对于为1的维度。比如:
1 | t = torch.randn((2,3,1)) |
out:
torch.Size([2, 3, 1])
torch.Size([2, 3])
torch.unsqueeze()
将数据维数进行扩充。比如:
1 | t = torch.randn((2,3,3)) |
out:
torch.Size([2, 3, 3])
torch.Size([2, 3, 1, 3])
torch.empty()
之前pytorch入门笔记01讲过,这里将如何赋值
1 | t = torch.empty(2,3) |
data找到对应的值,然后copy进去即可。
torch.split()
数据分割使用的
1 | images = torch.randn((3, 2, 2, 2)) |
四种padding模式
四个模式为Reflect,Zero,Replication,Constant。注意padding的大小不能超过matrix的大小。这部分的四个模式也是对应Convolution中的padding_mode设置。该设置有四种模式(’zeros’, ‘reflect’, ‘replicate’, ‘circular’)
一下例子以3 x 3大小的矩阵举例。这部分是pytorch源码中用的例子。
1 | testA = torch.arange(9, dtype=torch.float).reshape(1, 1, 3, 3) |
out:
tensor([[[[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]]]])
注意:还有这里就是所有的Pad参数都是填padding大小,ConstantPad当中需要在填入一个value。padding的参数如果是int就是周围都填充这么多。如果是一个有4个参数的tuple,表示的是左,右,上,下的顺序依次填充数量。
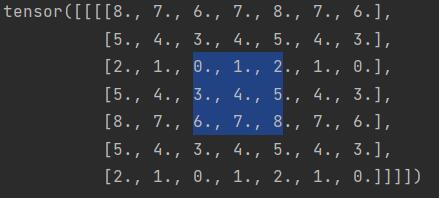
nn.ReflectionPad2d
字面意思镜像复制,就是以当前位置作为对称轴,将后面的值按照镜像翻转一份出来。
1 | reflectPadding = nn.ReflectionPad2d(2) |
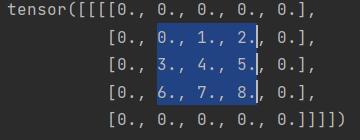
nn.ZeroPad2d
这个是使用0进行填充
1 | zerosPadding = nn.ZeroPad2d(1) |
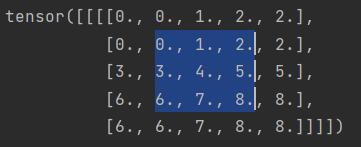
nn.ReplicationPad2d
复制填充,将周围的值复制一份填充到边框。
1 | replicationPadding = nn.ReplicationPad2d(1) |
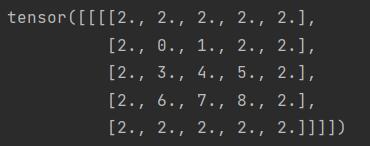
nn.ConstantPad2d
设定固定值作为填充
1 | constantPadding = nn.ConstantPad2d(1, 2) |
自动混合精度(torch.cuda.amp)
作用:减小显存占用,加快训练速度。
适用设备:支持Tensor Core的CUDA设备。
使用方式:torch.cuda.amp.autocast和torch.cuda.amp.GradScaler结合适用
混合精度:表示不止一种精度的Tensor,在AMP中有两种:FloatTensor,HalfTensor
自动:框架可以按需自动调整Tensor的dtype
为什么使用自动混合梯度
torch.HalfTensor优势:
存储小、计算快、更好利用Tensor Core,减少显存占用意味着可以多添加batchsize,训练加快。
torch.HalfTensor劣势:
数值范围小容易Overflow、舍入误差。
解决方案
- 梯度Scale,放大loss的值防止梯度underflow。
- 回落到torch.FloatTensor,至于什么时候回落这个由框架自行决定
使用方法
1 | model = Net().to("cuda") |
这里不需要在input上手动调用.half(),这个是框架自动去做的。
图片存储
1 | torchvision.utils.save_image(tensor, filename) |
或
1 | # 使用matplotlib |
nn.DataParallel数据并行
该方法在模块级别上实现了数据并行。相当nice的一个东西,当有多块显卡的时候,并且单块显存不足的时候,训练慢的时候都可以用。他做的工作是:将模块复制到每个设备上,每个副本都处理输入数据的一部分,然后在后向传递的过程中,每个副本的梯度会被累加到原始模块中。
注意 batch_size应该比GPU数量要多。
官方推荐使用的是DistributedDataParallel,来替代nn.DataParallel。即便只有一块卡,也是推荐使用DistributedDataParallel。两个重要区别就是DataParallel用的是多线程,DistributedDataParallel使用的是多进程。使用multiprocessing,每个GPU都有自己的专用进程,避免了python解释器GIL带来的性能开销。
DataParallel使用方法:
1 | net = Net() # 网络 |
如果用DataParallel的方法训练,参数拿下来,想本地CPU跑怎么办呢
同样使用torch.load()加载参数,但是记得设定map_location=“cpu”转到CPU上的参数,然后将参数进行调整。代码如下。
1 | check_point = torch.load("./model/net_parm.pth", map_location="cpu") |
DistributedDataParallel使用方法:
1 | import torch |
net.train()/eval()
对应修改的模型中的training属性,如果是train()方法,表示训练模式,training属性为True,可以在模型中控制在训练的时候,在模型中通过training属性进行判断,是否执行指定部分代码。如果调用eval(),表示是测试模式,training为False。
torch.where()
1 | torch.where(condition: Tensor, self, other) |
根据条件,将tensor修改。用法第一个参数是条件,第二个是条件为True的值,第三个是条件为False的值。
torch.as_tensor()和torch.from_numpy()
两者都是共享数据,所以转换tensor很快,且节省内存。可以推荐使用as_tensor(),因为as_tensor()可以接受任何像Python数据结构这样的数组。
1 | ''' |
调试工具
自动请求导异常检测
在训练模型的过程中,常常也会遇到。one of the variables needed for gradient computation has been modified by an inplace operation。这类似的问题。意思是一个变量需要计算梯度,但这个变量被就地操作修改。往往是出现在ReLu中的inplace参数设置为True的原因。但有时候也可能不是因为ReLu,可是报错也没有给出具体哪个地方的梯度设置问题,使用这个求导一场检测可以给出具体哪里出的问题。
使用:torch.autograd.set_detect_anomaly(True) 和 torch.autograd.detect_anomaly()
1 | import torch |