ANOSEG:用自监督学习的异常分割网络(论文学习)
这是自己读的第一篇英文论文,在其中发现自己有很多不会的知识点和术语之类的,现在还没完全读懂,目前记录学习到的知识补充,后续会继续补充。论文地址
知识点补充
IoU
IoU:(intersection over union)交并比,产生的候选框(Candidate bound)和原标记框(Ground Truth bound)的交叠率,就是交集和并集的比值
GT
GT: (Ground Truth)人工标注的正确label,训练集认为100%正确的标签。
SOTA
SOTA:(state of the art)技术发展最新水平。比如 SOTA model表示在该项研究任务中,目前最好/最先进的模型。
CoordConv
在原始的卷积层上面,添加两个层,一个是x坐标的层,一个是y层的坐标。给卷积添加了空间感知能力,在回归问题和分类问题上表现都比卷积效果更好。
python实现
1 | ins_feat = x # 当前实例特征tensor |
简单了解,代码转自https://blog.csdn.net/oYeZhou/article/details/116717210
这个论文还没有实现成功,这里只讲一下论文中的一些翻译以及我理解到的一些吧。等实现成功后会分享出代码以及最终跑出来的结果。
应用简介
异常分割是大规模工业制造中的一个重要部分,用来定位缺陷区域。该论文提出了一种新的异常分割网络能够通过自监督学习直接生成精确的异常图。
方法提出AnoSeg
AnoSeg是一个“整体”的方法,包括了三个技术:用硬增强自监督学习、对抗学习和坐标通道连接
用硬增强自监督学习
为了直接训练异常分割,需要一张有异常区域的图像和对应的GT mask。然而,在现实情况下很难获取到这些图片和GT mask。因此,提出使用硬增强的方法人工生成异常数据和GT Mask。硬增强指的是生成样本偏离原样本的分布。硬增强样本可以被用于作为负样本。因此正如图3,我们用硬增强的三种类型:旋转,置换,和颜色抖动。每个增强有50%被应用。接下来,将增强数据粘贴到正常数据的随机区域,生成合成异常数据和对应的分割mask。最终,异常分割数据组成如下:
Xseg是正常和生成异常图像的集合,Xnor和Xano对应的正常图像和合成异常图像。Aseg是正常和合成异常mask, 其中Anor和Aano分别对应正常mask里面的值全都是1和合成异常mask。
使用具有像素级损失的异常分割数据集,我们能够直接训练我们的AnoSeg。 异常分割损失Lseg如下:
其中Âseg表示的是生成异常图(正常和异常类型)。生成异常图有着和输入图像一样的大小,根据输入图像像素的重要性,对每个像素输出一个范围为[0,1]的值。然而,由于合成的异常数据只是各种异常数据的子集,很难生成在训练阶段看不到的真实异常图。
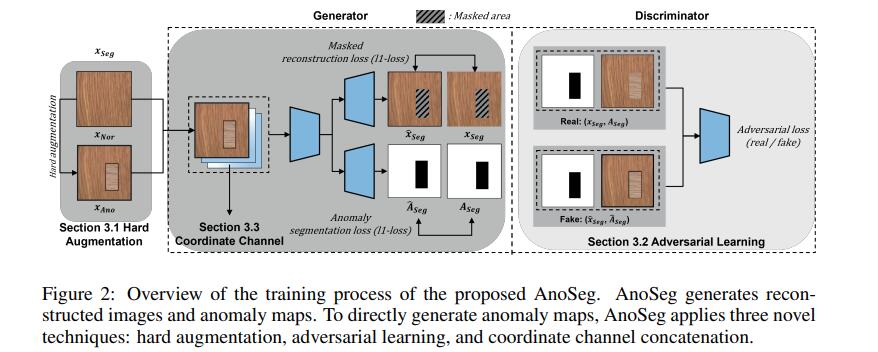
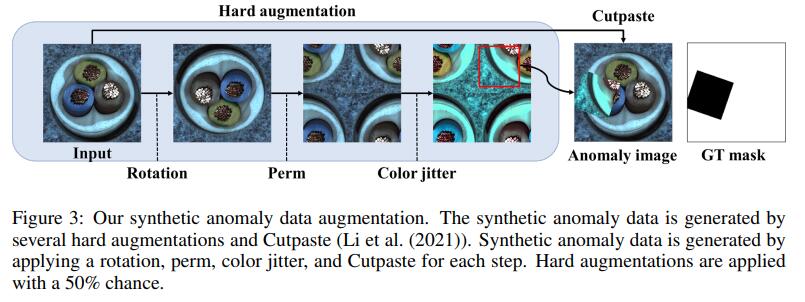
对抗学习和重建
为了提高对各种异常数据的通用性,训练正常区域分布准确性是很重要的。因此,AnoSeg利用只在正常区域使用重构损失的掩码重构损失,只学习正常区域的分布,避免了合成异常区域分布的偏差。此外,由于鉴别器为输入图像及其GT mask输入一对,判别器和发生器可以聚焦于正常区域分布。这样不仅不能很好地重建异常区域,而且还可以改善异常图的细节。对抗性学习的损失函数如下
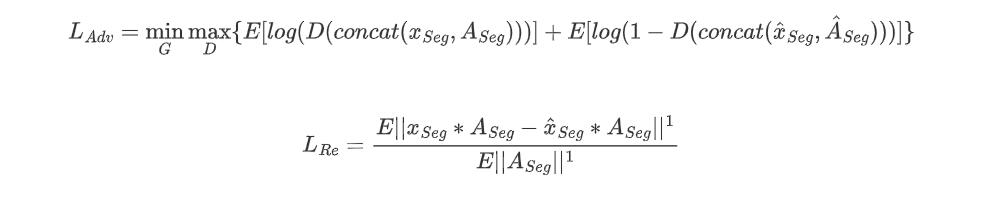
D,G和concat分别是 判别器(discriminator),生成器(Generator),和一个拼接操作。
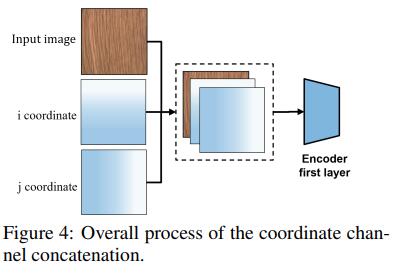
坐标通道连接
在传统的分割任务重,位置信息是最重要的信息。因为正常区域和异常区域会根据它们所处的位置发生变化。为了提供额外的位置信息,我们使用了受CoordConv启发的坐标向量。我们首先生成秩为1的矩阵,并归一化为[-1,1]。然后,我们将这些矩阵与输入图像作为通道连接(图4)。在消融实验中,我们证明了通道坐标连接的有效性。
使用提出的异常图进行异常检测
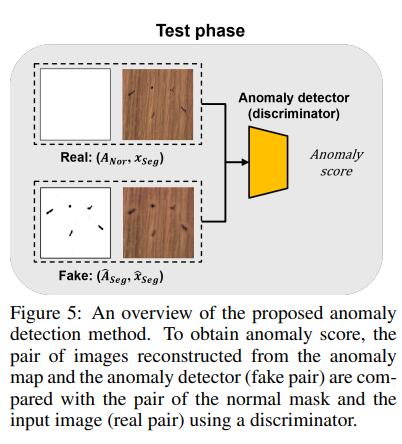
在本节中,我们设计了一个简单的异常检测器,将所提出的异常图添加到现有的基于gan的检测方法中。提出的异常检测器只通过学习正常数据分布来进行异常检测。我们简单地将输入图像和异常图连接起来,将它们作为检测器的输入,并同时应用对抗损失和经济结构损失。然后,我们使用(Salimans et al.(2016))引入的特征匹配损失来稳定鉴别器的学习并提取异常分数。我们在附录a中详细描述了异常检测的训练过程。在测试过程中(图5),所提出的异常检测器使用已学习到正常数据分布的判别器获得异常分数。我们首先假设输入的图像是正常的,因此所有内部值设置为1的mask ANor与输入图像成对使用。当输入图像为真正常时,假对(异常映射和重建图像)与真对(正常掩模和输入图像)相似,因此异常检测器的异常评分较低。另一方面,当输入图像异常时,假图像对与真实图像对差异显著,因此具有较高的异常评分。为了比较真实对和虚假对,使用重构损失和特征匹配损失如下:
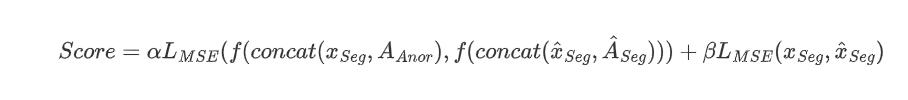
其中α和β的值分别是1和0.1. Anor和Lmse表示正常的GT mask 和均方差。
f(.)指的是鉴别器的倒数第二层。
训练方法以及网络结构
以上方法提出部分是对论文第3部分的翻译,讲的是三个技术的使用,以及最后对于异常图检测评分的方法。下面讲的是具体训练的方法,以及网络结构。也就是论文中的附录a部分以及附录b
异常检测方法的训练过程
本文提出的异常检测方法是将由anseg生成的异常图与输入图像结合,以了解正常图像和异常图的分布情况。因此,异常检测器在判断输入图像是否为正常图像的同时,判断异常图是否聚焦于输入图像的正常区域。与AnoSeg不同,提出的异常检测方法没有使用合成异常Xano作为一个对抗损失的真实类,因为异常检测的判别器对于异常检测只需要去学习正常数据分布。异常检测的判别器学习的损失函数如下:
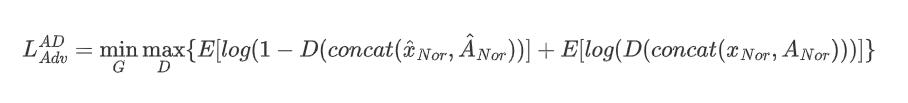
其中x^ nor,Ânor,xnor和Anor分别表示重构的正常图,AnoSeg的异常图,正常图,和正常mask
此外,为了帮助评估正常数据的分布,我们提出了一个区分合成数据和正常数据的合成异常分类损失。如(Odena(2016))所证实的,所提出的综合异常分类损失提高了鉴别器的异常性能。这种合成异常分类损失定义
然后,我们使用(Salimans et al.(2016))引入的特征匹配损失来稳定鉴别器的学习,提取异常评分。正常样本和重建样本的高级表示应该是相同的。这个损失如下所示
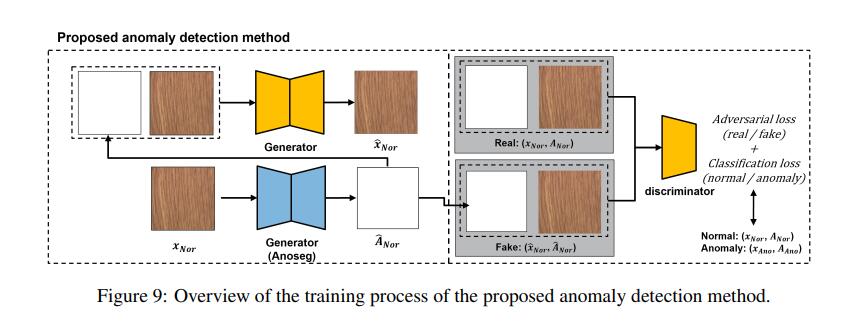
这里我在讲一下上面的图9,图9是训练异常检测的训练过程。首先输入一个正常图,接着进入了Generator,我觉得这个生成器就是图2的生成器。重构了一张异常图,将异常图和原图组合放入新的Generator,这个Generator的编码器是Discriminator一样的结构,解码出来一张重构的图像。这块重构的图像我没有去实现,直接用的AnoSeg中生成的图像。会不会是导致没有实现出来的原因。将重构的图像和重构的异常图连接,形成Fake,和实际上的真实组合Real(xnor,Anor)分别放入Discriminator,得到两个分数,Fake组合的分数要不断靠近0,Real组合分数不断靠近1。至于论文里面说的Loss feature该如何使用还不太清楚。
在说下图2吧,我觉的图2主要是讲的AnoSeg Generator训练过程。用来重构图像和重构异常图。先将图像进行硬增强,然后将图像添加两个通道,存放x坐标矩阵,y坐标矩阵。相当于一个5通道的图传入Encoder,Encoder最终生成8 8 512的一个code。有两个decoder,一个用来重构image,一个用来重构异常图的。训练Generator的时候,对于重构image的decoder使用的是对抗学习和重建里面的Lre重构loss,这个里面有个操作就是将异常mask和原图相乘,想一想之前说过异常图的范围是[0,1]之间。我们的GTmask,异常部分是0显示黑色,正常部分是1是白色,这样完成了图2中的mask area的遮挡。挡住异常部分,观察正常部分。对于重构。对于重构异常图(anomaly mask)的decoder使用的是在硬增强自监督学习中讲过,使用Lseg直接训练我们的AnoSeg。至于对抗学习重建当中讲的另一个公式,这个和GAN中讲的一样。在训练中貌似应该加上一个Generator生成图像给Discriminator得到评分,然后修改Generator的参数将评分不断逼近1。我实现的时候没有加上这个,可能是失败的原因之一吧。
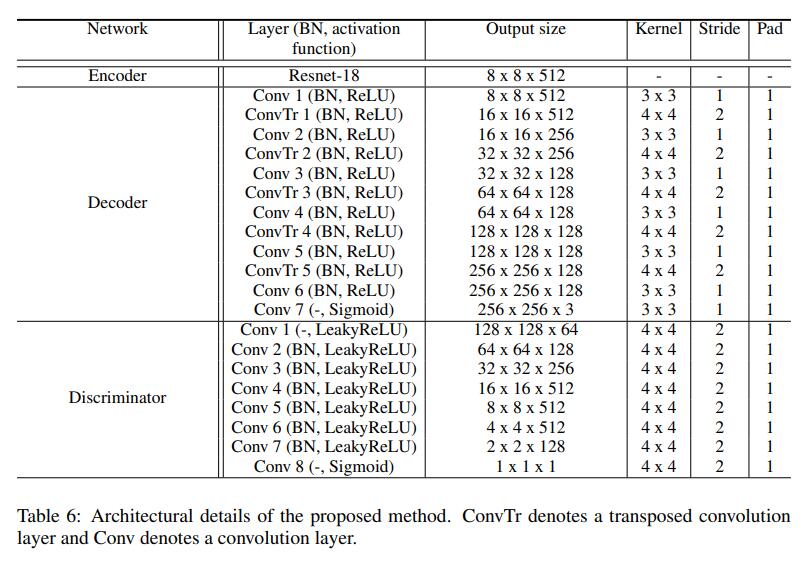
详细的网络架构
提出的方法网络结构如表6所示,每个网络是有一系列层描述,包括了输出形状,核大小,填充尺寸,步长。此外batch normalization(BN)和activation function分别是否应用BN和应用那个激活函数。用于图像重建的解码器与生成异常图的解码器结构相同,而AnoSeg使用了两个解码器。提出的异常判别结构也是和AnoSeg是相同的结构。