本文最后编辑于
过拟合 过拟合: 指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。
发生过拟合的原因:
模型拥有大量参数、表现力强
训练数据少
以下是故意产生过拟合的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from mnist使用.mnist import load_mnistimport numpy as npfrom MultiLayer import MultiLayerNetfrom WeightUpdate import *import matplotlib.pyplot as plt(x_train,t_train),(x_test,t_test) = load_mnist(normalize=True ) x_train = x_train[:300 ] t_train = t_train[:300 ] network = MultiLayerNet(input_size=784 ,hidden_size_list=[100 ,100 ,100 ,100 ,100 ,100 ],output_size=10 ) optimizer = SGD(lr=0.01 ) max_epochs = 201 train_size = x_train.shape[0 ] batch_size = 100 train_loss_list = [] train_acc_list = [] test_acc_list = [] iter_per_epoch = max (train_size / batch_size,1 ) epoch_cnt = 0 for i in range (1000000000 ): batch_mask = np.random.choice(train_size,batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] grads = network.gradient(x_batch,t_batch) optimizer.update(network.params,grads) if i % iter_per_epoch == 0 : train_acc = network.accuracy(x_train,t_train) test_acc = network.accuracy(x_test,t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) print ("epoch:" + str (epoch_cnt) + ", train acc:" + str (train_acc) + ", test acc:" + str (test_acc)) epoch_cnt += 1 if epoch_cnt >= max_epochs: break markers = {'train' :'o' ,'test' :'s' } x = np.arange(len (train_acc_list)) plt.plot(x, train_acc_list, label='train acc' ) plt.plot(x, test_acc_list, label='test acc' , linestyle='--' ) plt.xlabel('epochs' ) plt.ylabel('accuracy' ) plt.ylim(0 ,1.0 ) plt.legend(loc='lower right' ) plt.show()
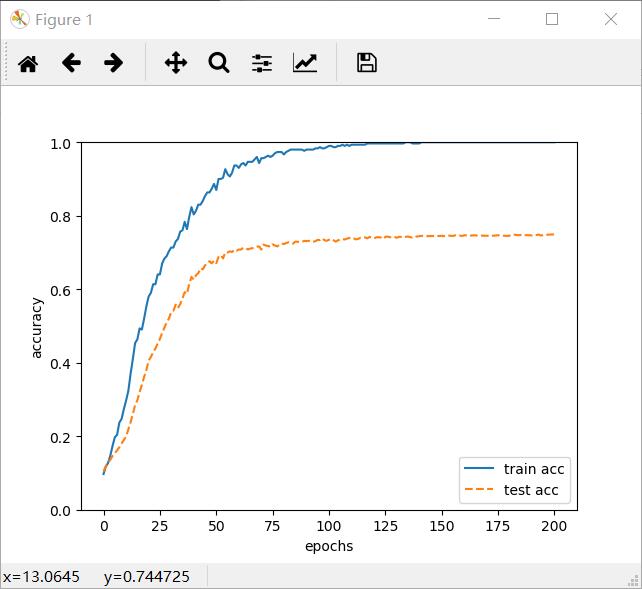
减少了训练数据为300,为增加网络复杂度,设定了7层网络,每层100个神经元。效果如下
可以看到测试数据识别精度到后边都是100%,而测试数据并不理想。
抑制过拟合 权值衰减 该方法通过在学习过程中对大的权重进行惩罚,来抑制过拟合。
具体操作:神经网络的学习目的是减小损失函数的值,这时损失函数加上权重的平方范数。即可抑制过拟合。也就是在计算loss的时候加上如下值:
python实现
1 2 3 4 5 6 7 8 def loss (self,x,t ): y = self.predict(x) weight_decay = 0 for idx in range (1 ,self.hidden_layer_num + 2 ): W = self.params['W' + str (idx)] weight_decay += 0.5 * self.weight_decay_lambda * np.sum (W ** 2 ) return self.last_layer.forward(y,t) + weight_decay
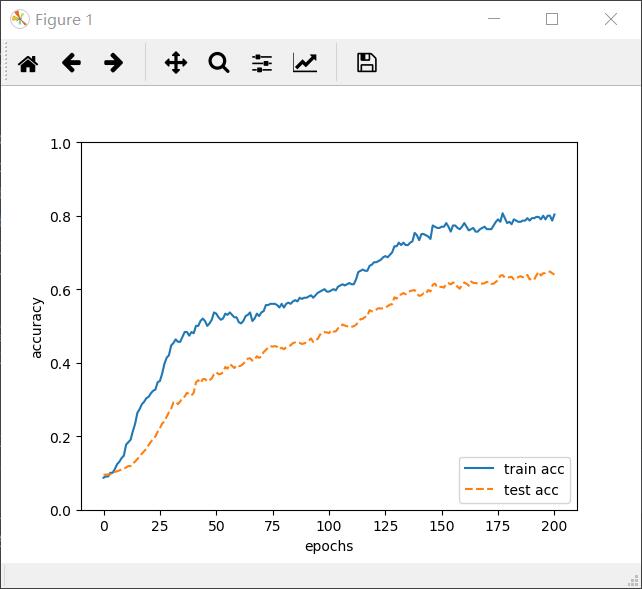
λ=0.1时的图像
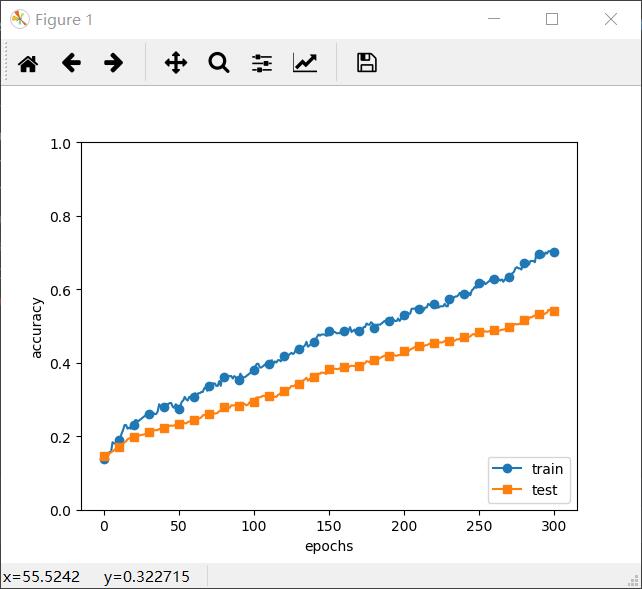
Dropout Dropout是一种通过在学习过程中随机删除神经元的方法。
python实现
1 2 3 4 5 6 7 8 9 10 11 12 13 import numpy as npclass Dropout : def __init__ (self,dropout_ratio = 0.5 ): self.dropout_ratio = 0.5 self.mask = None def forward (self,x,train_flg = True ): if train_flg: self.mask = np.random.rand(*x.shape) > self.dropout_ratio return x * self.mask else : return x * (1.0 - self.dropout_ratio) def backforward (self,dout ): return dout * self.mask
卷积神经网络 全连接层: 相邻层的所有神经元之间都有连接。
卷积层 学过opencv的知道,卷积的意思,边缘检测的sobel算子,双边滤波,高斯模糊,掩模操作都是用到的卷积。卷积核就是将一个nxn的矩阵,里面有不一样的权重,将对应像素的值乘上权重后相加,成为中间的值。同样的概念引用到这里。
卷积核 也称为滤波器 ,填充 就是做卷积图像边上的一圈填入固定值,步幅 就是滤波器的位置间隔。
特征图: CNN中,卷积层的输入输出数据。有输入特征图 ,输出特征图
输出图像大小计算 假设:
输入大小为 (H,W) H: high, W: width
滤波器大小为 (FH,FW) FH: Filter High, FW: Filter Width
步幅为 (S) S: Stride
填充为 (P) P: Padding
池化层 池化是缩小高、长方向上的空间的运算。常见的是Max池化(将目标区域中取出最大元素)
池化层的特征 没有要学习的参数: 池化只是目标区域中最大值(或平均值)。
通道数不会变化: 经过池化运算,输入输出的通道数不会变化。
微小位置变化具有鲁棒性: 输入数据发生微小偏差时,仍会返回相同结果。
卷积层实现 util工具下载
python实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from common.util import im2colfrom common.util import col2imimport numpy as npclass Convolution : def __init__ (self,W,b,stride=1 ,pad = 0 ): self.W = W self.b = b self.stride = stride self.pad = pad self.x = None self.col = None self.col_W = None self.dW = None self.db = None def forward (self,x ): FN,C,FH,FW = self.W.shape self.x = x N,C,H,W = x.shape out_h = int (1 + (H + 2 *self.pad - FH) / self.stride) out_w = int (1 + (W + 2 *self.pad - FW) / self.stride) self.col = im2col(x,FH,FW,self.stride,self.pad) self.col_W = self.W.reshape(FN,-1 ).T out = np.dot(self.col,self.col_W) + self.b out = out.reshape(N,out_h,out_w,-1 ).transpose(0 ,3 ,1 ,2 ) return out def backforward (self, dout ): FN, C, FH, FW = self.W.shape dout = dout.transpose(0 ,2 ,3 ,1 ).reshape(-1 , FN) self.db = np.sum (dout, axis=0 ) self.dW = np.dot(self.col.T, dout) self.dW = self.dW.transpose(1 , 0 ).reshape(FN, C, FH, FW) dcol = np.dot(dout, self.col_W.T) dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad) return dx
池化层实现 python实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import numpy as npfrom common.util import im2colfrom common.util import col2imclass Pool : def __init__ (self,pool_h,pool_w,stride=1 ,pad=0 ): self.pool_h = pool_h self.pool_w = pool_w self.stride = stride self.pad = pad self.x = None self.arg_max = None def forward (self,x ): N, C, H, W = x.shape out_h = int (1 + (H - self.pool_h) / self.stride) out_w = int (1 + (W - self.pool_w) / self.stride) col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad) col = col.reshape(-1 , self.pool_h * self.pool_w) arg_max = np.argmax(col, axis=1 ) out = np.max (col, axis=1 ) out = out.reshape(N, out_h, out_w, C).transpose(0 , 3 , 1 , 2 ) self.x = x self.arg_max = arg_max return out def backforward (self, dout ): dout = dout.transpose(0 , 2 , 3 , 1 ) pool_size = self.pool_h * self.pool_w dmax = np.zeros((dout.size, pool_size)) dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten() dmax = dmax.reshape(dout.shape + (pool_size,)) dcol = dmax.reshape(dmax.shape[0 ] * dmax.shape[1 ] * dmax.shape[2 ], -1 ) dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad) return dx
CNN实现 有了卷积层和池化层,现在可以组合这些层,完成搭建MNIST识别的CNN。网络结构如下
Image Input -> Conv -> ReLu -> Pooling -> Affine -> ReLu -> Affine -> Softmax
该类命名为SimpleConvNet。
初始化参数
input_dim :输入数据的维度:(通道,高,长)
conv_param :卷积层的超参(字典)。字典key如下:
filter_num: 滤波器的数量
filter_size: 滤波器大小
stride: 步幅
pad: 填充
hidden_size: 隐藏层(全连接)的神经元数量
output_size: 输出层(全连接)的神经元数量
weight_int_std: 初始化时权重的标准差
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 import numpy as npfrom collections import OrderedDictfrom Convolution实现 import Convolutionfrom ReLU层 import Relufrom Affine import Affinefrom max 池化层 import Poolfrom SoftmaxWithLoss import SoftmaxWithLossclass SimpleConvNet : def __init__ (self, input_dim=(1 ,28 ,28 'filter_num' :30 , 'filter_size' :5 , 'pad' :0 , 'stride' :1 }, hidden_size=100 , output_size = 10 , weight_init_std=0.01 ): filter_num = conv_param['filter_num' ] filter_size = conv_param['filter_size' ] filter_pad = conv_param['pad' ] filter_stride = conv_param['stride' ] input_size = input_dim[1 ] conv_output_size = (input_size - filter_size + 2 * filter_pad) / filter_stride + 1 pool_output_size = int (filter_num* (conv_output_size/2 ) * (conv_output_size / 2 )) self.params={} self.params['W1' ] = weight_init_std * np.random.randn(filter_num, input_dim[0 ], filter_size, filter_size) self.params['b1' ] = np.zeros(filter_num) self.params['W2' ] = weight_init_std * np.random.randn(pool_output_size,hidden_size) self.params['b2' ] = np.zeros(hidden_size) self.params['W3' ] = weight_init_std * np.random.randn(hidden_size,output_size) self.params['b3' ] = np.zeros(output_size) self.layers = OrderedDict() self.layers['Conv1' ] = Convolution(self.params['W1' ], self.params['b1' ], conv_param['stride' ], conv_param['pad' ]) self.layers['Relu1' ] = Relu() self.layers['Pool1' ] = Pool(pool_h=2 ,pool_w=2 ,stride=2 ) self.layers['Affine1' ] = Affine(self.params['W2' ],self.params['b2' ]) self.layers['Relu2' ] = Relu() self.layers['Affine2' ] = Affine(self.params['W3' ],self.params['b3' ]) self.last_layer = SoftmaxWithLoss() def predict (self,x ): for layer in self.layers.values(): x = layer.forward(x) return x def loss (self,x,t ): y = self.predict(x) return self.last_layer.forward(y,t) def gradient (self,x,t ): self.loss(x,t) dout = 1 dout = self.last_layer.backforward(dout) layers = list (self.layers.values()) layers.reverse() for layer in layers: dout = layer.backforward(dout) grads = {} grads['W1' ] = self.layers['Conv1' ].dW grads['b1' ] = self.layers['Conv1' ].db grads['W2' ] = self.layers['Affine1' ].dW grads['b2' ] = self.layers['Affine1' ].db grads['W3' ] = self.layers['Affine2' ].dW grads['b3' ] = self.layers['Affine2' ].db return grads def accuracy (self, x, t, batch_size=100 ): if t.ndim != 1 : t = np.argmax(t, axis=1 ) acc = 0.0 for i in range (int (x.shape[0 ] / batch_size)): tx = x[i * batch_size:(i + 1 ) * batch_size] tt = t[i * batch_size:(i + 1 ) * batch_size] y = self.predict(tx) y = np.argmax(y, axis=1 ) acc += np.sum (y == tt) return acc / x.shape[0 ]